3
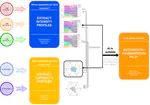
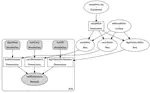
The project develops a framework for assessing the suitability of large language models for workforce tasks. It links annotated AI benchmarks, model performance evaluations, LLM capability profiles, and human work activities to estimate how suitable different LLMs are for specific job domains. The framework can be used to inform decisions about which models to pilot for particular workforce activities. Presentation describing the project and results can be found here.