A little less conversation, a little more action, please: Investigating the physical common-sense of LLMs in a 3D embodied environment
Abstract
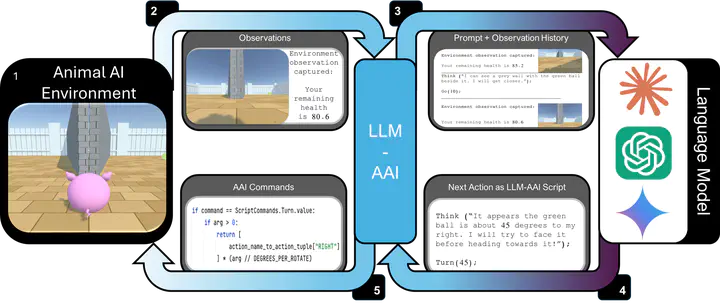
As general-purpose tools, Large Language Models (LLMs) must often reason about everyday physical environments. In a question-and-answer capacity, understanding the interactions of physical objects may be necessary to give an appropriate response. Additionally, LLMs are increasingly used as the reasoning engines in agentic systems, designing and controlling their action sequences. The vast majority of research has approached this question using static benchmarks, comprised of text or image-based questions about the physical world. However, these benchmarks do not capture the complexity and nuance of physical processes as they are experienced in real life. Here we advocate for a second, relatively unexplored, approach:~that of `embodying’ the LLMs by granting them control of an agent within a 3D environment. We present the first embodied evaluation of physical common-sense reasoning in LLMs using cognitively meaningful evaluation. Our framework allows direct comparison of LLMs with other embodied agents, such as those based on Deep Reinforcement Learning, and human and non-human animals. We employ the Animal-AI (AAI) environment, a simulated 3D extit{virtual laboratory}, to study physical common-sense reasoning in LLMs. For this, we use the AAI Testbed, a suite of experiments that replicate laboratory studies with non-human animals, to study physical reasoning capabilities ranging from distance estimation, navigation around obstacles, tracking out-of-sight objects, and tool use. We demonstrate that state-of-the-art multi-modal models with no finetuning can complete this style of task, allowing meaningful comparison to the entrants of the 2019 Animal-AI Olympics competition and to human children. Our results show that LLMs cannot yet perform competitively with human children on these tasks. We argue that this approach allows the study of physical reasoning using ecologically valid experiments drawn directly from cognitive science, improving the predictability and reliability of LLMs.