I am a Senior AI Analyst at the Department for Science, Innovation and Technology (DSIT), working on the impacts of AI on labour markets and the economy. My work includes modelling the effects of AI on productivity and workforce change, assessing AI adoption, and supporting policy on AI skills and adoption.
Previously, I was a Research Associate at the Leverhulme Centre for the Future of Intelligence, University of Cambridge, where I worked on AI evaluation. This included assessing the validity of benchmarks, evaluating the capabilities of large language models, and mapping AI capabilities to job tasks in the human workforce. This research was supported by the OECD.
Before that, I was a Royal Academy of Engineering UK IC postdoctoral research fellow investigating the impact of explanations of AI predictions on our beliefs. I also worked people’s causal and probabilistic reasoning and have a strong interest in data analysis and Bayesian modelling.
I received a Ph.D. in Psychology from Birkbeck’s Psychological Sciences department, an M.A. in Logic and Philosophy of Science from the Munich Center for Mathematical Philosophy, LMU and a B.A. in Philosophy from University of Belgrade, Serbia. See my CV for more info on my background, research and work experience.
I play the violin in Paprika: The Balkan and East European band.
Projects
Publications
Evaluating Generalization Capabilities of LLM-Based Agents in Mixed-Motive Scenarios Using Concordia
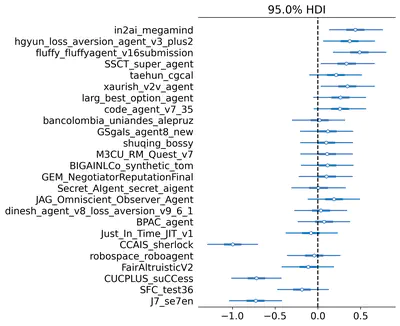
We evaluate the general cooperative intelligence of LLM-based agents in zero-shot, mixed-motive environments using a natural language multi-agent simulation, showing limited generalisation to novel social situations.

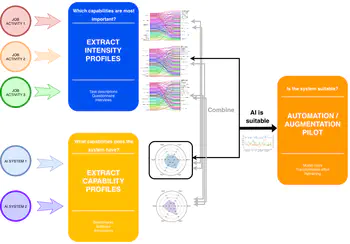
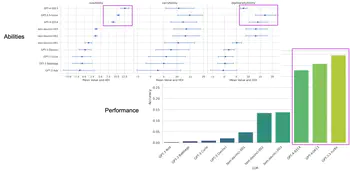
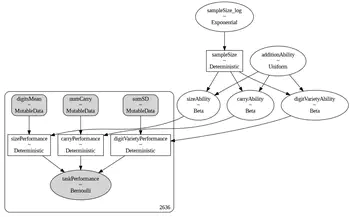
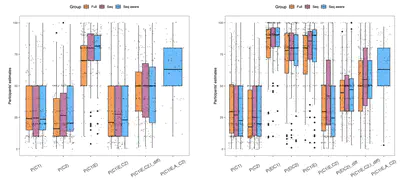
Beyond the high score: Prosocial ability profiles of multi-agent populations
We use a Bayesian approach called ‘Measurement layouts’ to infer prosocial capability profiles of multi-agent systems in the Melting Pot testbed, showing that high performance does not always reflect strong cooperation abilities.
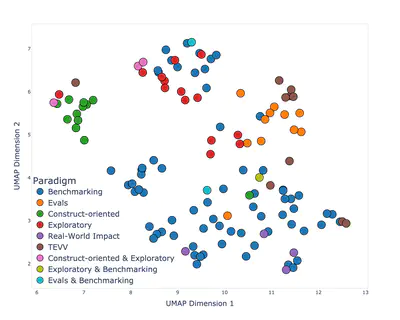
Paradigms of AI Evaluation: Mapping Goals, Methodologies and Culture
We analyse 125+ evaluation studies and identify six major paradigms of AI evaluation, each shaped by distinct goals, methodologies, and research cultures.
Benchmark Design Criteria for Mathematical Reasoning in LLMs
I lay out key benchmark design criteria for evaluating mathematical reasoning in LLMs.
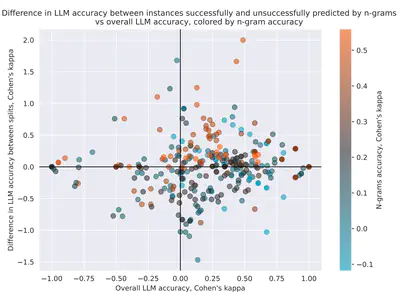
Leaving the barn door open for Clever Hans: Simple features predict LLM benchmark answers
We explore whether benchmarks can be solved using simple n-gram patterns and whether LLMs exploit these patterns to solve benchmark tasks.

A little less conversation, a little more action, please: Investigating the physical common-sense of LLMs in a 3D embodied environment
Evaluation of the physical common-sense reasoning abilities of LLMs (Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro) by embedding them in a 3D environment (Animal-AI Testbed) and comparing their performance to other agents and human children.
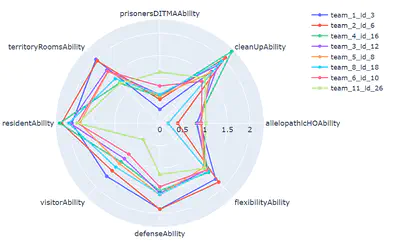
Melting Pot Contest: Charting the Future of Generalized Cooperative Intelligence
An analysis of the design and outcomes of the Melting Pot competition, which measures agents’ ability to cooperate with others. We developed cognitive profiles for the agents submitted to the competition.
Testing the maximum entropy approach to awareness growth in Bayesian epistemology and decision theory
Applying the Maximum Entropy approach to awareness growth in the Bayesian framework, i.e. incorporating new events that we previously did not consider possible.
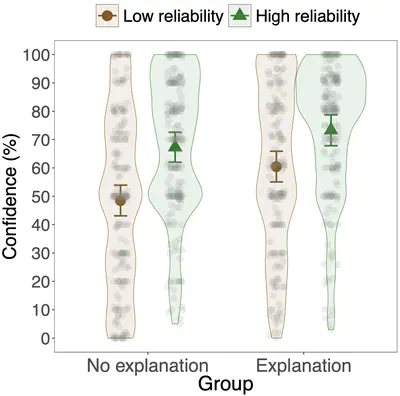
The impact of explanations as communicative acts on belief in a claim: The role of source reliability
Investigating the effects of (good) explanations and the explainer’s reliability on our beliefs in what is being explained.
Argument and explanation
We bring together two closely related, but distinct, notions: argument and explanation. We provide a review of relevant research on these notions, drawn both from the cognitive science and the artificial intelligence (AI) literatures. We identify key directions for future research, indicating areas where bringing together cognitive science and AI perspectives would be mutually beneficial.
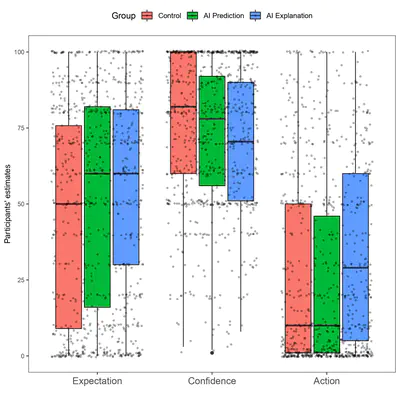
Can counterfactual explanations of AI systems’ predictions skew lay users’ causal intuitions about the world? If so, can we correct for that?
We explore some of the undesirable effects of providing explanations of AI systems to human users and ways to mitigate such effects. We show how providing counterfactual explanations of AI systems’ predictions unjustifiably changes people’s beliefs about causal relationships in the real world. We also show how health warning style messaging can prevent such a change in beliefs.
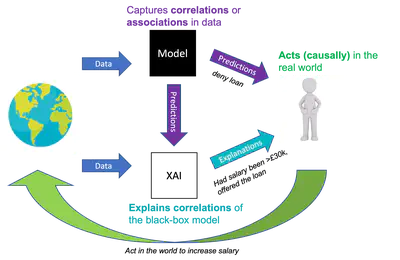
On the transferability of insights from the psychology of explanation to explainable AI
A discussion of the consequences of directly applying the insights from the psychology of explanation (that mostly focuses on causal explanations) to explainable AI (where most AI systems are based on associations).
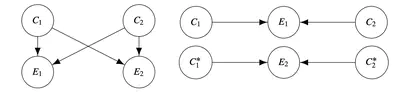
Explanation in AI systems
What do we do with our existing models when we encounter new variables to consider? Does the order in which we learn variables matter? The paper investigates two modeling strategies and experimentally tests how people reason when presented with new variables and in different orders.
The propensity interpretation of probability and diagnostic split in explaining away
Empirical testing of the effects of the propensity interpretation of probability and ‘diagnostic split’ reasoning in the context of explaining away.
Widening Access to Bayesian Problem Solving
An experimental exploration of whether a Bayesian network modeling tool helps lay people to find correct solutions to complex problems.
Sequential diagnostic reasoning with independent causes
What do we do with our existing models when we encounter new variables to consider? Does the order in which we learn variables matter? The paper investigates two modeling strategies and experimentally tests how people reason when presented with new variables and in different orders.
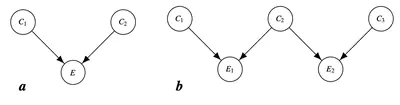
Explaining away: Significance of priors, diagnostic reasoning, and structural complexity
Investigating people’s reasoning in explaining away situations by manipulating the priors of causes and the structural complexity of the causal Baeysian networks.
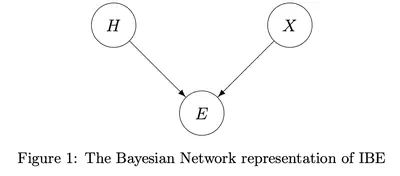
Confirmation by Explanation: A Bayesian Justification of IBE
A justification for Inference to the Best Explanation (IBE) is provided by identifying conditions under which the best explanation of evidence can offer a confirmatory boost to the hypotheses under consideration.
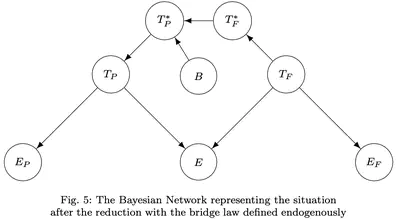
Confirmation and the Generalized Nagel-Schaffner Model of Reduction: A Bayesian Analysis
Analyzing confirmation between theories in cases of intertheoretic reduction (e.g. reducing thermodynamics to statistical mechanics) using Bayesian networks.
Past Projects

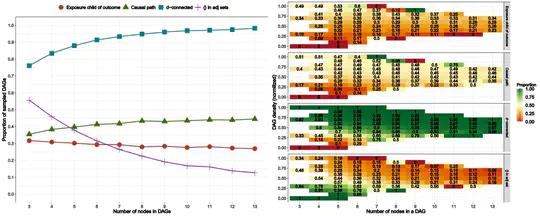
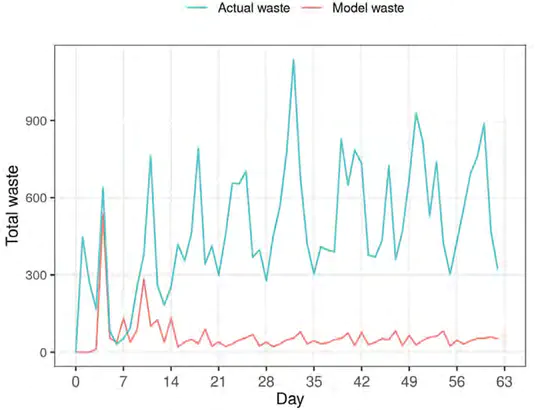
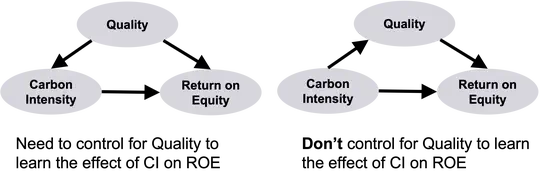
Contact
My email address is marko dot tesic375 little monkey gmail dot com.